春节期间手机完全被DeepSeek-R1刷屏了, 无论是海内外媒体都疯狂讨论DeepSeek-R1. 趁着假期返工花了一整天大致了解了DeepSeek-R1的实现主体. 之后刚好同一天Andrej Karpathy发了Deep Dive into LLMs like ChatGPT. 查阅了一天资料, 有些心得. 写下此文, 也是记录自己如何了解新的技术.
记录
20250206:0910 早上到公司
目标: 了解DeepSeek-R1以及为什么R1会这么火
背景: 无任何关于DeepSeek-R1的资料阅读, 没读过论文
20250206:0932 动作: 刷hacker news关于deepseek的post, 看各个thread的观点
* 动作: 跟着Simon Willison的blog(DeepSeek-R1 and exploring DeepSeek-R1-Distill-Llama-8B)实现本地ollama跑DeepSeek-R1-Distill-Llama-8B-GGUF
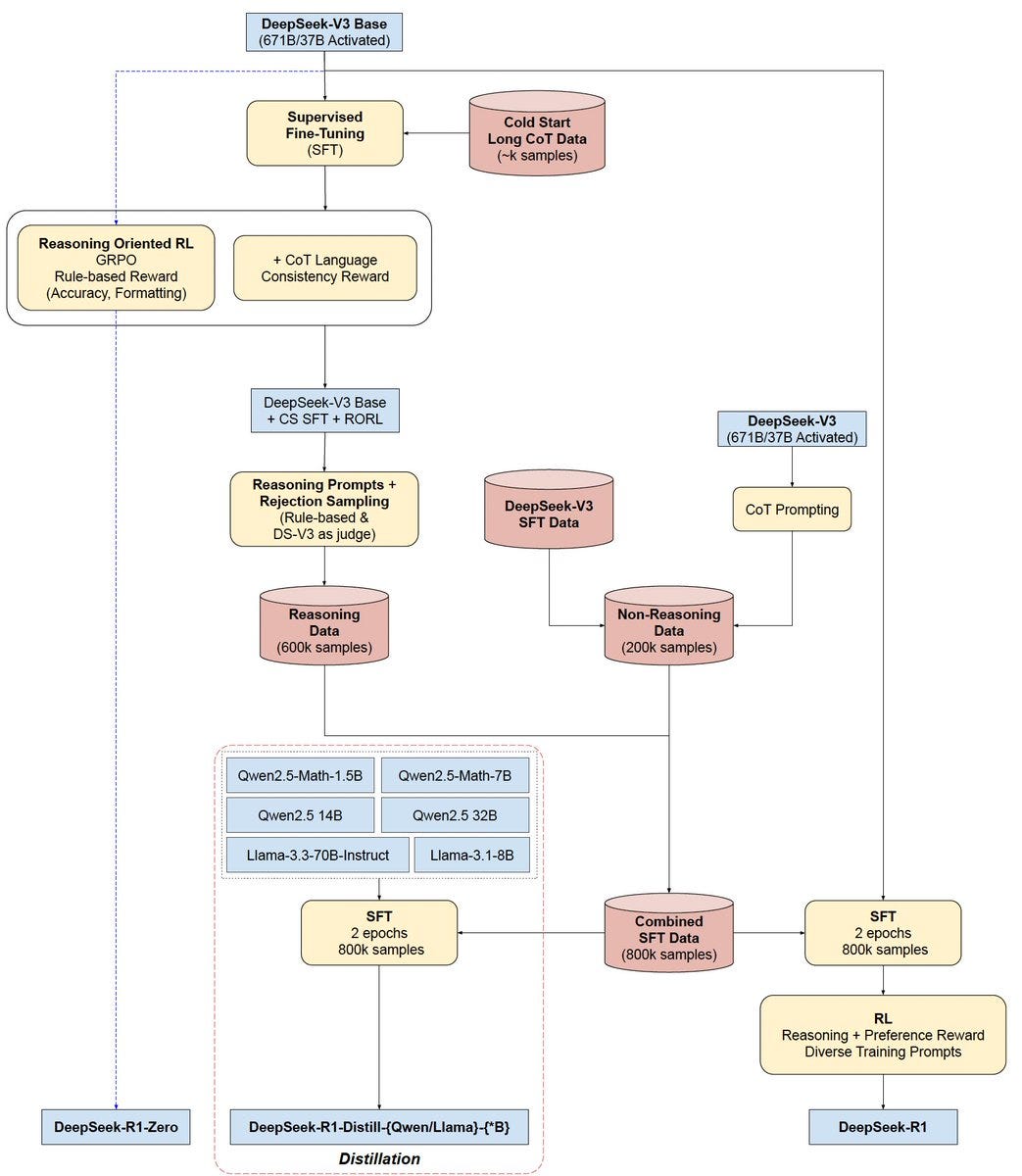
* 收获: 了解了DeepSeek-R1-Zero, DeepSeek-R1以及DeepSeek蒸馏模型的关系.
20240206:1014 动作: 看yt视频# DeepSeek R1 Theory Overview | GRPO + RL + SFT
* 收获:
* 整个DS-R1被训练出来的脉络, 博主画了个图, 表达很清楚, 见附录[1]
* 什么是GRPO以及GRPO公式大概的含义
* 相比于OpenAI闭源的COT推理能力[2], DS开源了如何实现推理模型
* 知道了GRPO是R1的重点
20240206:1030 动作: 看yt视频: # Group Relative Policy Optimization (GRPO) - Formula and Code
* 衍生动作:
* 看yt video视频 # Proximal Policy Optimization (PPO) - How to train Large Language Models
* 看了看知乎上关于GRPO的讨论和解析
* 收获:
* 了解了PPO的大致流程
* 大致了解了GRPO, 但还是不懂, 需要找个场景实现一下. #TODO
* 刷到了王兴兴关于GRPO的讨论和解析[3], 深入研究下GRPO在机器人控制的应用中 #TODO
20240206:1414 动作: 看yt视频 # Building a fully local "deep researcher" with DeepSeek-R1
* 收获:
* 了解了如何用langchain使用r1达到像openai deep research类似的效果, 以后可以考录用api部署一个试下 #TODO
20240206:1442: 动作: 看yt视频 # Paper: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
* 收获:
* 自回归模型的输出可以被看成是一个RL的过程
* 大致跟着视频过了一遍论文, 没仔细看
* 这个视频长度大概一个小时, 百分之80的时间都在讲GRPO, 所以GRPO一定是R1的重点.
20240206:16:00 - 20240207:11:30: 动作: 看yt视频 # Deep Dive into LLMs like ChatGPT
* 收获(这个视频是我看到关于LLM最干的视频, 强烈推荐观看原版3个小时):
* LLM的训练流程为预训练(Pre-Training)产生基座模型(Base Model),
但是Base Model不具有对话的能力, 因此要通过后训练(Post Training),
通过SFT(Supervised Fine-Tuning)的方式, 输入多轮对话的数据, 来让
模型有对话的能力. 最后通过Post Training RL, 来让模型有推理能力.
* PreTraining阶段, 数据集和分词过程决定了Base Model的效果
* PreTraining阶段, 通过不断改变context size, 模型能够实现in context learning能力
* 由于Base Model本质上根据互联网数据的词语接龙, 因此幻觉一定会存在
* 幻觉可以通过改变post training SFT的数据集, 或者使用tool use能够减少
* 模型需要更多的token去做思考
* 模型不擅长做in memory computing
* 要让模型能在post training中实现tool use的能力,就是在SFT中加入pre training没见过的token
* knowledge in the parameters => vague recollection
* knowledge in the token of context window => working memory
* 以人阅读一本教材进行学习为例, 训练模型学习书中的背景知识就是pre training, 学会书中的例题称为post training. 而完成课后习题就是post training with RL
* 在最后一个阶段post training with RL, 需要喂模型课后题(prompt), 并且人类给出打分. 由于这个过程需要进行很多次, RLHF通过拟合人类回答的偏好. 来实现自动训练.
* RLHF不算RL, 而是微调模型来达到人类偏好
* DeepSeek R1的aha moment和AlphaGo Zero的Aha moment很像, 训练效果都是非线性的, 一开始上升非常缓慢, 到了某一刻急速上升.
* 通过[4]可以了解AI的最新动态
* 通过[5]可以了解AI的排名
总结
之前我也在别的地方刷到R1实现了更低成本的训练, 例如使用PTX而不是raw cuda等, 这算infra层的创新. 但是我看的视频下来 开源的推理模型, 以及纯RL而不用SFT(DeepSeek-R1-Zero) 或许是R1更大的意义.
剩下的TODO
- 找一个场景复现PPO以及GRPO
- 刚好在2月7号, o3-mini开源了思维链的过程, 对比一下
- 了解下RL-LLM的现状, 输出一篇文章
- 阅读R1原文, 自己总结一下, 并对比这篇文章, 了解更多的技术细节.
- pi0开源了, 研究下pi0
- 借助xxx平台提供的api, 实现一个属于自己的deep research. 也算是往agentic ai迈了一步.
- 总结下DS的发展路线, 输出一篇文章
附录
[1] (yt video # DeepSeek R1 Theory Overview | GRPO + RL + SFT)各个模型关系图
[2] Hiding the Chains of Thought - OpenAI
[3] DeepSeek GRPO在简单控制系统上和PPO的对比
[4] AI News
[5] LM Arena for model rankings
20240208更新
接着上片文章, 在2月7日的时候, 我一直在找如何请求deepseek-r1 api的方式. 因此现在ds大火, 服务器一直繁忙. 想找个渠道试一下r1都难. 也尝试了硅基流动以及一些其他的api提供商. 因为是尝试, 不太想直接往api服务商充钱. 于是, 截至到今日(20250208), 我试下来有两种免费方式可以请求deepseek-r1.
目前这两个平台的api请求是免费的, 无问苍穹会快很多, 并且api的速度远比不上playground. 并且两个平台的api稳定性都不太好, 会有请求失败的问题. 之后, 我用cursor写了一个适配于百度千帆的命令行工具. 效果如下.

顺便试了下百度的其他免费的模型, 响应速度还行. 仓库链接点击这里

{kind=link}