五分钟读论文: Scaling and evaluating sparse autoencoders
这几天OpenAI新发了一篇博客关于使用sparse-autoencoders去解释GPT4的内部机制. 本文是对论文的解读方便读者快速获取关键信息, 如果好求甚解, 请点击传送门:
- blog: Extracting Concepts from GPT-4
- paper: Scaling and evaluating sparse autoencoders
- code: openai/sparse_autoencoder
目录
如果对背景知识不太了解的话, 推荐顺序阅读. 如果已经有足够的背景知识, 请点击这里开始正文阅读. 下面是对论文的解读.
背景知识
Autoencoder
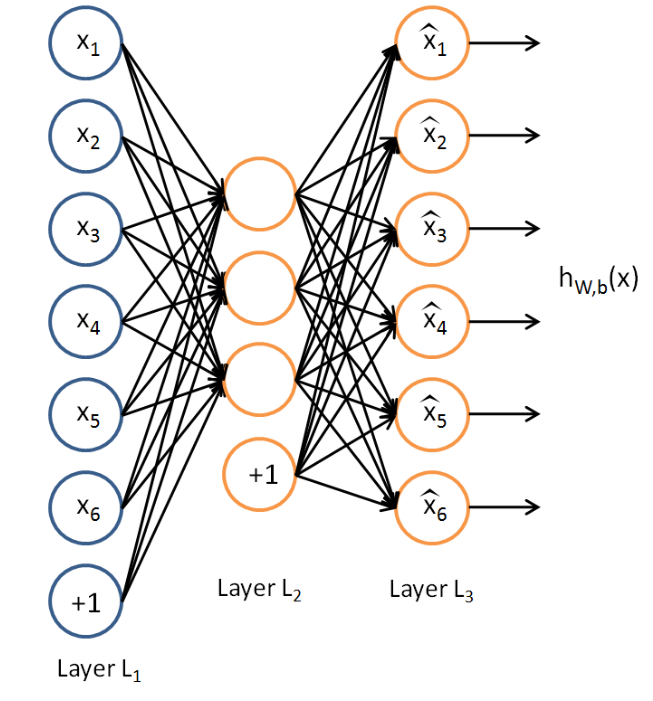
根据吴恩达在CS294A的讲义, Autoencoder是一种无监督学习, 在没有给定标签的数据{x(1), x(2), x(3)....}, 通过隐藏层(hidden layer)学习输入中隐含的特征, 从而让输出{x^(1), x^(2), x^(3)...}尽可能的逼近输入. 下图为autoencoder的结构(引用自这里):
Sparse Autoencoder
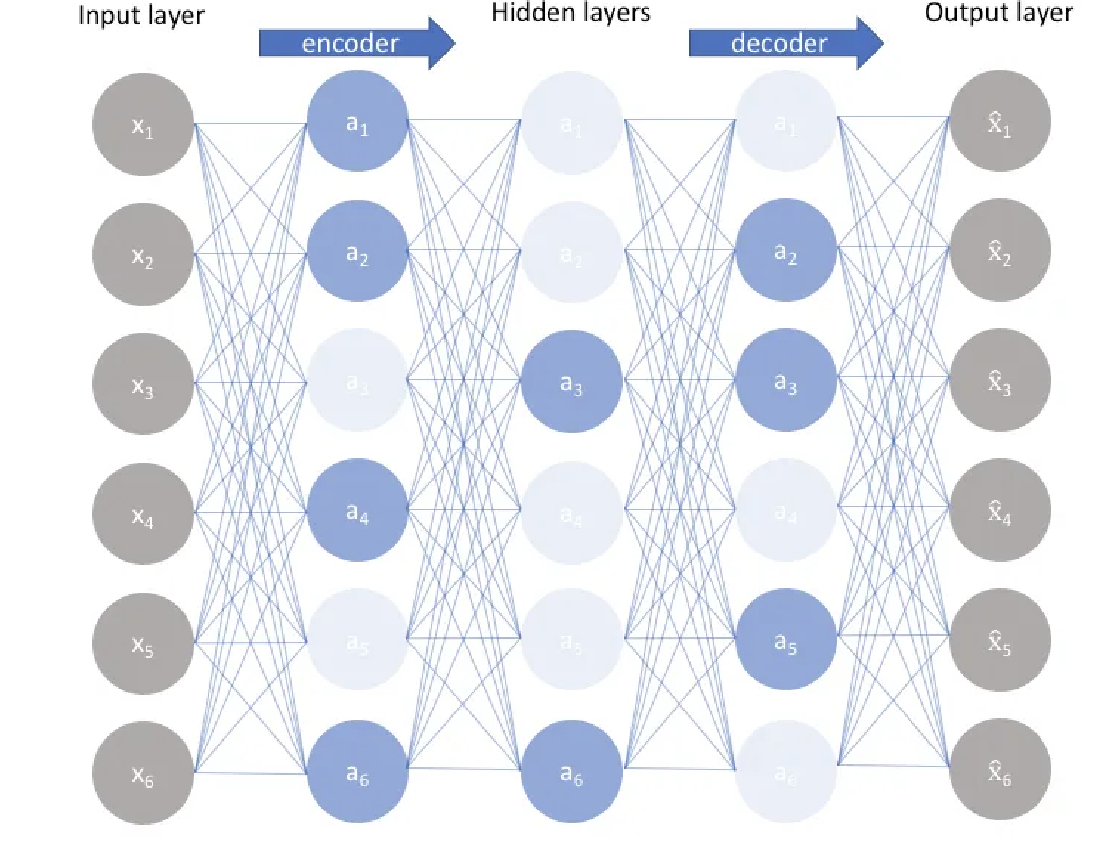
Sparse Autoencoder是Autoencoder的一种变种, 在Autoencoder的基础上通过增加稀疏惩罚项(sparse penalty)使得前向传播时只有一部分神经元激活, 而不是所有神经元都激活. 由于相比与未做稀疏化处理的autoencoder结构, 激活的隐藏层神经元(hidden neruon)变少了, 因此每一个隐藏层神经元都包含了更丰富的隐藏特征(latent feature). 是不是和现在流行的Mixture of Experts很像? 下图为sparse autoencoder的结构(引用自这里):
Sparse Autoencoder的特征可解释性
MIT6.S898 Deep Learning在2023年发表的一篇blog在这里提到了
A sparse autoencoder lets us learn a sparse representation for a vector, but in a higher dimensional space.
相比与未稀疏化的Autoencoder, 稀疏化的Autoencoder可以学习到更高维度的隐含特征. 换个角度说, 未经稀疏化的隐藏层神经往往是表示多维特征(polysemantic). 而经过稀疏化的隐藏层神经元所表示的特征维度更少, 从而使得隐含特征更加容易理解. 更详细的关于sparse autoencoder的可解释性, 可以点击Anthropic发的"Towards Monosemanticity: Decomposing Language Models With Dictionary Learning"查看.
Bottleneck Layer
bottlenect layer指的是含有比前一层更少的神经元的网络层, 使得输入特征维度减少. 这里引用英文原文更方便理解:
A bottleneck layer is a layer that contains few nodes compared to the previous layers. It can be used to obtain a representation of the input with reduced dimensionality.
TopK激活函数
TopK是一种激活函数. 仅保留输入向量中最大的k的值,其余值设置为0.
论文解读
ok, 我们已经了解了所有的前置知识, 接下来我们开始看这篇文章. 首先是作者部分还有Ilya Sutskever与Jan Leike, 说明是OpenAI之前研究的存货. 再来看摘要部分:

黄色部分的文字是这篇文章所解决的问题, 绿色部分是作者提出的解决方案.
- 问题 : 随着输入特征的增加, 训练sparse autoencoder会难以平衡稀疏性与准确性. 稀疏性指的是如何确定哪些神经元需要激活, 哪些神经元不需要激活. 准确性是指经过稀疏化处理后的隐藏层神经元所表示的隐含特征是否与原始输入特征相似(见背景知识Autoencoder).
- 解决方案 : 作者使用k-sparse autoencoder去控制稀疏性从而实现平衡.
到了正文部分, 作者一开始比较了不同的激活函数对autoencoder的影响. 发现TopK的获得最小的正规化均方根误差(Normalized root mean square error). 如下图所示:
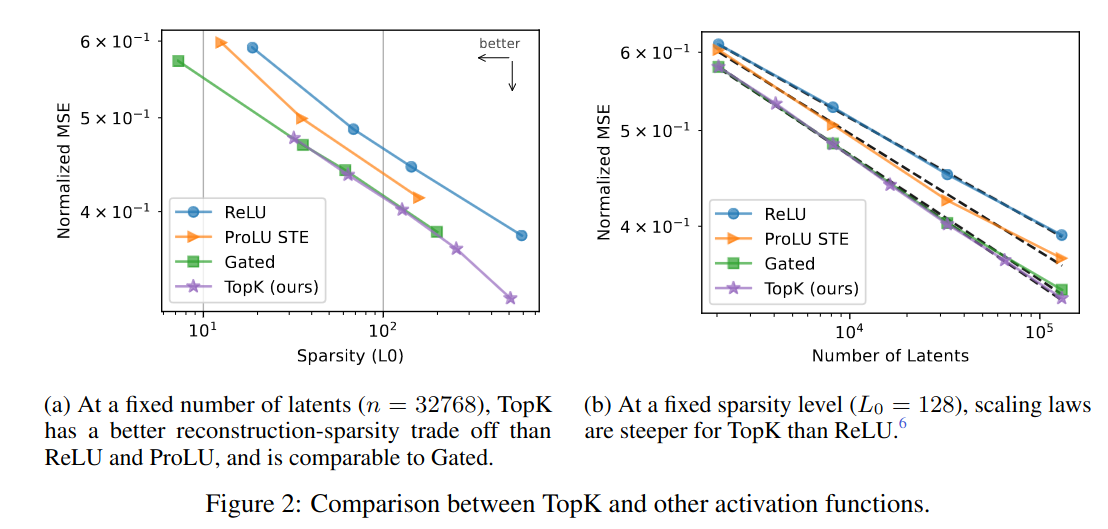
接下来作者在不同指标上又进行了测试, 如果有兴趣建议阅读原文. 为了抓住重点, 我们先跳过这一部分. 作者使用Neuron to Graph(N2G)去做特征的解释.
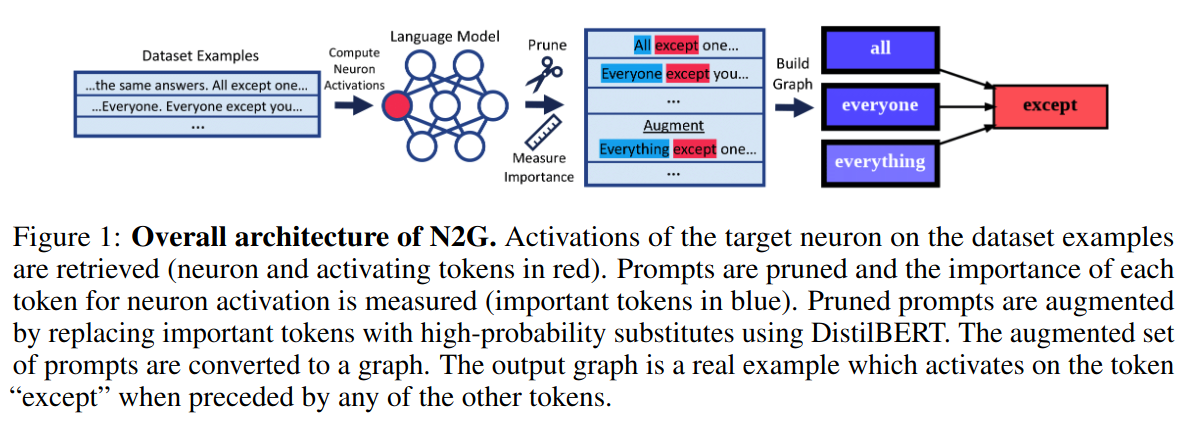
上图的N2G论文原文的描述, 可以看到N2G是将语言模型输出的回答进行关联生成一张有向图.
之后作者对比了ReLU与TopK在N2G中的表现. 发现TopK的召回率以及精度都更高. 如下图所示:
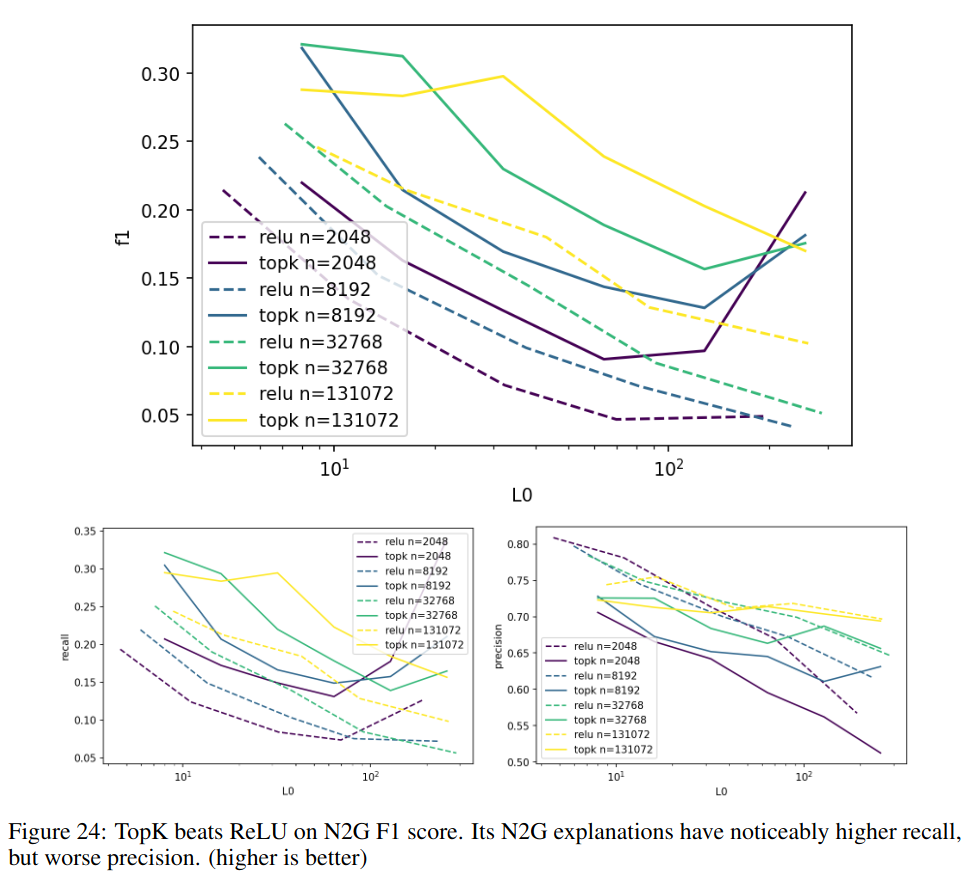
最后作者给出了结论以及未来工作的方向:

参考资料
- Sparse autoencoder, CS294A Lecture notes - Andrew Ng
- What does a bottleneck layer mean in neural networks?
(第一次写这种论文解读类文章, 发现还是不好写. 因为有条件的话应该直接读原文, 不加如一些原文的图的话会表达不到意思, 加了太多又和读原文没什么区别.)