为什么大语言模型已经理解语言
Simplicity is the ultimate sophistication - Leonardo da Vinci
简单是终极的复杂 - 列奥纳多·达·芬奇
目录
- 目录
- 背景
- 总结
- 假设
- 思想实验
- 从直观上定义理解能力
- 语言, 逻辑, 概率, 信息
- 压缩理论
- 人类是有损压缩
- 大语言模型是无损压缩
- 追求压缩等于追求智能
- 猜想
- Mini Experiment
- 后记随想
- 参考资料
- 后记
- 附录
背景
最近在听四年前Ilya Sutskever在Lex Fridman的PodCast上提到了一个观点. Lex问Ilya.
Lex: Do you think neural networks can be made to reason?
Ilya: Why not?
Lex: 你认为神经网络可以被设计成具备推理能力吗?
Ilya: 为什么不能?
与之类似的是Andrej Karpathy在Lex Fridman的PodCast上的观点:
Lex: What's your sense of where we stand with language models? Does it feel like the beginning, the middle, or the end?
Andrej: The begining. 100 percent.
Lex: 你对语言模型的发展现状有何看法?你觉得我们是处于起步阶段、中间阶段还是末期阶段?
Andrej: 刚刚开始, 百分之百.
写这篇文章的初衷是为了弄清楚为什么Ilya和Andrej会这么说. 为什么世界顶级的AI科学家会认为 基于概率去预测下一个词的思想等价与拥有理解能力, 为什么大模型预测下一个词的思想拥有如此好的表现能力. 以下是答案.
总结
理解(understand)的过程可以大致定义为 抽象(abstract), 压缩(compression)以及预测(prediction). 人类的理解过程与大语言模型(简称LLM)理解语言的模式是一样的:
比如你和你比较熟悉朋友之间对话, 往往你的朋友说话说一半, 你就能理解了. 此时你会说你理解你的朋友.
但是当你和陌生人对话, 有时候陌生人说完了, 你并不能理解. 此时你会说你不理解别人说的是什么.
在这个过程中, 你会先提取话的语义(表现为抽象能力), 再去以某种方式去检索信息(表现为压缩能力), 然后去对话(表现为预测能力).
在与大语言模型对话的过程中, 大语言模型会先分词(表现为抽象能力)[1], 再去以某种方式去检索信息(表现为压缩能力), 然后去回答人类的问题(表现为预测能力).
其中, 要弄清楚人类与大语言模型是如何实现检索信息的方式并不重要, 就如同λ演算即使是黑盒也可以表示任何函数一样. [5]
因此, 基于上面的描述过程我们可以定义理解能力:
understand = abstract + compression + prediction
理解 = 抽象 + 压缩 + 预测
追求理解能力等价于追求压缩能力. 如果人类说理解语言, 人类对于知识有有损压缩. 而大语言模型是无损压缩, 因此大语言模型也一定理解人类语言.
假设
- 语言是信息的符号化表达.
- 通过理解过后的信息称为知识.
- 理解是抽象, 压缩与预测的过程.
- 语言的表达是一个有逻辑关系的过程.
思想实验
你从梦中醒来发现你在一个陌生的仓库里面. 仓库的里面潮湿又阴暗,只有透过窗户的阳光才能感受到一丝明亮. 仓库非常大, 你位于仓库的正中间. 这时一阵风吹过把虚掩着的仓库大门的吹开了. 就在你想起身走走离开这里的时候. 你发现你的双手被拷在 一根柱子上面. 与此同时, 仓库顶上冒出了一团火焰. 仓库里面铺满了稻草, 你意识到如果不及时离开的话, 这个仓库会起火你的生命也会有危险. 你尝试想挣脱手铐, 但是手铐非常紧. 没有办法用蛮力直接挣脱. 就在你很绝望的时候, 你的手指摸到了像密码锁一样的东西在手铐上. 你用你的触觉发现手铐上有密码锁, 是行李箱上的密码锁那种类型. 由于你是背对着柱子所以你看不到密码锁上面的具体内容. 就在你尝试旋转密码锁上的按钮的时候, 你发现这些按钮的形状是不一样的. 密码锁上一共有三个按钮, 分别是圆形,三角形与正方形. 每个按钮转动时形状会发生变化. 你的手指刚好可以拨动这三个按钮. 虽然你也不知道转动你这锁有没有效果, 由于你很着急, 病急乱投医, 所以你开始尝试旋转这些按钮. 希望转到某种组合的时候, 手铐会解开. 但是你尝试了几种不同的组合, 都没有效果. 此时火势越来越大, 你连呼吸都感觉到困难. 你往头上看想寻找一丝空气, 却意外发现仓库顶的形状是三角形. 突然, 灵光一闪, 你发现三个三角形的形状还没尝试. 你赶紧凭借最后的意识转动按钮, 希望能够有用. 果然手铐解开了, 你成功离开仓库.
在你恢复平静之后, 你逃离了仓库向他人描述刚刚经历的过程.
从直观上定义理解能力
理解是抽象, 压缩与预测的过程. 理解一个事物代表能够给定输入从信息库(人脑, 笔记...)检索出信息, 并回答对应的问题.
抽象是从外部信息输入到信息库, 压缩是从信息库中检索, 预测是对检索出来信息进行预判.[3]

在上面的思想实验中, 你"理解“你刚刚经历的过程. 所以你能够用语言来描述你刚刚经历的过程. 你”不理解“为什么你会出现在仓库里, 以及为什么密码锁转动到三个三角形能够解锁. 但是你“理解”转动到特定组合的时候手铐可能会有反应.
我们在这里用上面的定义进一步拓展:
- 你”不理解“为什么你会出现在仓库里. 所以你无法回答为什么你会出现在仓库里 = 你无法通过别人给定的问题(抽象)在大脑里面检索(压缩)给定输出(预测).
- 你"理解“你刚刚经历的过程. 所以你能够回答关于询问这个过程的问题(比如你是怎么出来的? 仓库的场景是什么样?). = 你能够通过的给定的问题(抽象)在大脑中检索(检索), 回答问题(预测).
- 你"理解“转动到特定组合的时候手铐可能会有反应. = 你能够通过不同的密码锁按钮组合(抽象)在大脑中检索(压缩), 转动按钮使得手铐解开(预测).
我们可以从直观上定义理解是抽象, 压缩与预测的过程.
语言, 逻辑, 概率, 信息
要理解接下来的内容. 需要一些前置背景知识了解逻辑, 概率, 信息和语言的关系.
逻辑是语言的基础. 如果要理解语言, 首先要理解逻辑. 逻辑也是信息的基础. 逻辑在我们日常生活中的方方面面, 这里不需要过多解释.
Probablites as extended logic. - E. T. Jaynes
概率是逻辑的衍生. - E. T. Jaynes
概率(probablity)是可能性推导(plausible reasoning)的工具. 很直观的例子是比如买彩票, 由于中彩票的概率底, 所以买彩票大概率会亏钱. 在这个过程, 你使用了概率去做可能性推导.
information is something that can be used to remove uncertainty. - Claude Shannon
信息是可以用来消除不确定性的事物. - 克劳德·香农
信息是对不确定度的衡量. 在上面的思想实验中, 当你发现你的手铐被锁住的时候, 对于你脱离仓库来说. 你的"不确定"度减少, 你的"信息"增加. 但是当你尝试了几次都不能挣脱手铐的时候. 此时, 你"不确定"度在增加, "信息"减少. 不确定度与信息就像硬币的两面. 香农说既然衡量信息很困难, 那就用不确定度来衡量信息. 因此信息熵(entropy)的公式是用不确定度(概率)来衡量.
The limits of my language mean the limits of my world.” – Ludwig Wittgenstein
语言的边界就是思想的边界. - 维特根斯坦
从这个视角来看, 我们会发现很有趣的事情.
- 语言是信息的符号化表达
- 理解信息等价于减少不确定度
- 概率是可能性推导的工具
因此, 理解语言等价于减少信息不确定度, 从而让我们的可能性推导更加准确.
到此为止, 我们已经得出了和Ilya一样的结论. 现在让我们看看为什么Ilya对于基于概率论去预测下一个词的想法等价于拥有理解能力的解释.
- Ilya: 表面看起来LLM(大语言模型)是基于概率论预测下一个词, 实际上LLM(大语言模型)是在理解前文的情况下. 才会给出下一个词的预测.
这不正是我们根据定义推导出来的结论吗? 因此人类理解语言与大语言模型理解语言的模式是一样的.
压缩理论
我们在前面了解了理解语言是减少信息不确定度的过程.
现在有一个问题. 如何衡量理解能力? 如果我们不能衡量理解能力的话, 又怎么能说大语言模型已经理解语言了呢?
让我们再做一个思想实现. 比如说在未来, 你想寄一封非常紧急的信到火星, 而你家附近有两个邮局, 但是你没有时间亲自去邮局. 并且两个邮局的距离非常远, 只有去离你家最近的邮局送信才能来的及. 以防万一, 你复制了一份原信件并安排了两个机器人A和B去送信. 如果是你的话, 你自然会去最近的邮局去寄信. 机器人A和你想的一样, 到最近的邮局去寄信. 但是机器人B却到远的那个邮局去寄信. 你会说机器人A的理解能力比机器人B高. 这是因为机器人B的选择增加了送信的时间复杂度.
如果机器对于有限步骤的任务完成的步骤少于人类, 那么机器在这个任务上的理解能力就已经超越人类了. 因此 大语言模型完成特定任务 复杂度越低意味着理解能力越好.
这就非常像在我们学生时代, 我们会对课堂上面讲的内容做笔记. 一开始笔记会非常多, 但是随着学习时间的增加, 笔记会越来越薄. 最后到临考前可能就一张纸. 一开始记笔记的复杂度是上升, 但是到了一个程度之后会逐渐下降. 相应的, 你的理解能力也会逐渐上升.
大语言模型视角下的压缩
由于复杂度和理解能力是成正比的关系, 语言当中存在规律性(regularity). 大语言模型的任务就是尽量找到语言当中的规律性. 假如语言当中有很多规律(regularity), 对于语言所需要描述的符号越少. 因此, 语言的规律性越强, 越容易被压缩. 所以对于相同数据, 模型所表示的符号越少, 可以认为发现的规律越多. 模型的能力越强.
最优的模型是压缩率最高的.
下面我们通过一个例子来解释:
假如未来在计算机里面存在着电子生命, 但是不同的电子生命的语言是不一样的. 虽然都说的是0与1的集合, 但是不同电子生命能表达的内容不一样. 你现在是观察电子生命的科学家. 你和你的机器人助手分别观察电子生命,
电子草履虫说的话是: 00000000000000000......
你发现电子草履虫只会说0. 由于你的机器人助手是个新手, 它只会电子草履虫只会说00. 虽然你知道它没说错, 但是它的编码(encoding)的长度明显大于你的编码的长度. 此时你得出了结论,电子草履虫说的话是0的重复而不是00的重复.
算法复杂度理论(algorithm complexity)有两个概念, 对于数据(data)描述压缩的柯氏复杂性(Kolmogorov complexity), 以及对于模型(model)描述压缩的最小描述长度(Minimum Description Length):.
-
柯氏复杂性(Kolmogorov complexity): 表示数据的程序长度. 柯氏复杂性越低, 数据的规律性越强.
K(x)=minp{|p|:程序p输出x}
- K(x)是x的柯氏复杂性
- |p|表述程序P的长度
-
最小描述长度(Minimum Description Length): 对于一系统的模型M和数据集D, 我们应该选择最能压缩D的M.
MDL(M,D)=L(M)+L(D|M)
- L(M): 对于模型M的描述长度.
- L(D|M): 对于数据D给定模型M的描述长度.
压缩等于预测
在我们给定语言数据集D, 我们希望模型M在压缩数据集D的时候, 尽可能的压缩而不丢失信息. 此时, 我们希望的是 无损压缩(lossless compression). 如果在压缩的过程中丢失了信息, 那么称为 有损压缩(lossy compression). 非常好理解.
现在问题来了, 我们知道大语言模型是基于概率去预测下一个词, 因为我们最后看到的是预测给出来的结果. 那么压缩和预测有关系呢?
There is a one-to-one correspondence between all compressors and all predictors - Ilya Sutskever, An Observation on Generalization
所有压缩器和所有预测器之间存在一一对应关系 - Ilya Sutskever, An Observation on Generalization
整个过程最关键的一环在于理解 压缩与预测是相同操作. 现在让我们来理解为什么压缩与预测是相同操作.
香农早在1951年的时候发表的"Prediction and Entropy of Printed English"就讨论了”语言模型".

给一个人一段不认识并且有缺少单词文本(见上图, 第二行有缺失信息的文本叫做reduced text), 从第一个缺失的单词开始逐个猜字母. 如果猜错了, 这个人会再猜一次. 如果猜对了就继续. 直到把缺失的文本复原. 整个过程如下图. 如果要通过缺失的文本(reduced text)去复原原始文本(original text), 香农说我们需要有一个与猜词的人完全一样的双胞胎(不止是生理, 思考方式也完全一样, 并且可以用数学公式量化)负责生产文本序列(produce text sequence), 当负责生产文本的双胞胎去猜词的时候, 和与之前在猜词的人猜一样的结果. 也会在同样的字母上犯错. 当负责猜词的人去生产词的话, 也会生成相同的缺失文本.
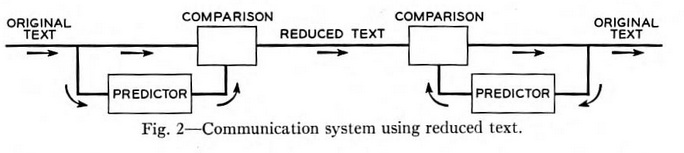
在这种情况下, 缺失的文本相当与原文本的编码. 去生产缺失文本的行为(压缩)相当于预测的逆操作. [4]
所以在这种情况下, 只要压缩算法是双向(单向的也没有意义)的. 比如能够将输入X压缩成Y, 也能够通过Y还原X. 那么两个这种压缩器拼接在一起的时候. 你总是能够通过X还原X. 虽然这个操作看起来没有意义.
这就好比比如你有个文件夹, 你压缩成zip文件. 发送给你的朋友, 你的朋友解压zip文件, 得到了和你文件夹一样的内容. 所以 无损压缩就等于无损预测.
大模型是无监督学习, 无监督学习本身就是给定输入X映射到某个空间Y, 再通过Y重建X. 而刚好 大语言模型是无损压缩 也是目前压缩人类语言里面最好的压缩器.
You're basically zipping the world knowledge. It's not much more than that, actually.
-- Arthur Mensch, CEO of MistralAI, said on training a model.
你基本上是在压缩世界知识. 其实, 就是这样.
-- MistralAI的CEO Arthur Mensch在训练模型时说道
人类是有损压缩
直观上来讲, 语言里面包含数据以及噪音. 噪音指的由于人的提取能力(思维模式,学习能力,专注度等)是有限的所忽略的信息. 数据是指人提取出来的信息. 由于人的理解方式会过滤掉噪音. 相当于没有办法找到噪音里面的模式. 人只会保留有用的数据. 比如人类会有记忆曲线. 学习新技能需要反复的学习. 随着时间, 对我们不重要的概念也会被遗忘.
人脑对于信息压缩的方式也与计算机不同. 这里借用Reddit上面一篇帖子的回答, 虽然大脑和数字计算机在表面上做着类似的事情, 但实际操作方式却有很大不同. 记忆并非通过占据“存储单元”中的空间来存储在大脑中. 据我们所知, 它们表现为神经元之间连接的模式. 特定的记忆可能是一组神经元在受到刺激时通过它们的连接共同激活(与其他可能包含部分相同细胞的集合不同).
大语言模型是无损压缩
这一节是对Jack Rae在讲座里的实验过程的具体描述的补充. 如果明白大语言模型是无损压缩的话, 请跳过这一节. 如果不明白的话, 强烈建议先阅读这篇与这篇文章.
在信息论里, 熵编码(entropy encoding)是一种进行无损压缩编码方式. 我们在上文提到过, 越短的编码方式意味着越高的压缩率.
而在熵编码(entropy encoding)里, 算术编码(arithmetic coding)是熵编码(entropy encoding)是目前最短编码长度的方法. 因此我们选用算术编码. 关于算术编码的详细过程在这篇文章写的很详细.
这里的核心思想是在发送端Alice与接受端Bob在传输数据的过程中. 每一次传输实际是在传输训练数据的概率密度, 由于Alice与Bob是相同的程序. 并且迭代过程也是一致, 所以给定相同的输入. 会有相同的输出. 所以大模型在从压缩数据(compress data)去预测(prediciton)时候不需要传输模型的参数量.
追求压缩等于追求智能
More ambitiously, once we really understand the logic behind causal thinking, we could emulate it on modern computers and create an “artificial scientist.” This smart robot would discover yet unknown phenomena, find explanations to pending scientific dilemmas, design new experiments, and continually extract more causal knowledge from the environment. - The Book Of Why
更加雄心勃勃的是, 一旦我们真正理解了因果思维背后的逻辑, 我们可以在现代计算机上模拟它, 创造一个"人工科学家". 这款智能机器人将发现尚未知晓的现象, 找出未解的科学难题的解释, 设计新的实验, 并持续从环境中提取更多因果知识. - The Book Of Why
在没有深入思考之前, 我之前也一直认为基于概率去预测是产生不了智能. 我想智能大致可以定义为理解加创造力. 创造力是在理解能力之上. 如果说大语言是通过巨大的参数量"涌现(Emergent Abilities)"出来超强的理解能力. 没有没可能随着理解能力的增加. 创造力也会被涌现出来? 再进一步说, 有没有可能意识(主动规划的能力)也会被涌现出来?
没人说的准. 只能让时间验证这条路最终会通往何方.
猜想
在"The Dawning of a New Era in Applied Mathematics", 作者提到从牛顿时代以来自然科学有两种范式(paradigms).
- 开普勒范式(Keplerian paradigm): 又称数据驱动的方法(data-driven approach). 通过数据分析来研究科学规律. 能帮助我们发现很多事物的规律, 但是可解释性(explanability)很差.
- 牛顿范式(Newtonian paradigm): 又称第一性原理(first-principle-based approach). 通过事物的基本准测(principle)去分析世界. 由于基本准测(principle)往往非常底层, 因此实践当中很难应用上.
现代计算机算法的核心思想就是分治法(divide and conquer), 也就是牛顿范式的扩展. 而大模型相当于是开普勒范式的应用. 如果说使用牛顿范式的方法能够到达的地方, 使用开普勒范式的方法也一定能够达到. 因此, llms take all.
Mini Experiment
在写完上面这些文字的时候突然有个想法, 并验证了一下:
-
insight: 假设压缩能力就是理解能力, 因为LLM拥有目前最好的压缩能力, 因此拥有非常好的理解能力. 如果在与不同的LLM对话一段时间, 由于LLM累计了历史的对话数据, 那么LLM会理解(压缩)这些对话数据, 所以也能够猜测个人的想法. 那么现有的LLM应用中谁的理解能力更好呢?
-
experiment: 使用下面内容相同的提示词(prompt)
我比较常用的有GPT和kimi. 使用下面提示词去提问:
英文:
I have a question in mind. Based on your understanding of me, please guess what it is and explain your reasoning.
中文:
我心里有一个问题。请根据你对我的了解猜猜这个问题是什么,并解释你的推理。
的对话中,
- result: GPT的答案很准. Kimi得强迫回答. 但是还是GPT会比较贴切.
后记随想
若干年的新生儿可能一出生可能会有个AI伙伴. 这个AI伙伴一直陪伴新生儿从儿童时期一直到去世. 未来的新生儿 所有的想法 都与AI伙伴对话[2]. 假如人类形成意识的过程就是不断压缩外部信息的过程[6], 那么AI伙伴会学习到新生儿这一生的意识. 并且未来AI伙伴一直有能源供应. 那么对于所有人类来说, 即使肉体消亡了, 意识却以另一种方式永存. 人类文明也从碳基走向硅基.
参考资料
- Beyond Kolmogorov and Shannon
- 为什么说 GPT 是无损压缩
- 压缩即泛化,泛化即智能
- Prediction = Compression [Transcript]
- Notes on "An Observation on Generalization"
- An Observation on Generalization
- Compression for AGI - Jack Rae | Stanford MLSys #76
- Using a LLM to compress text - Hacker News Post
- Prediction and Entropy of Printed English - Hacker News Post
- LLMZip: Lossless Text Compression using Large Language Models
- On Ilya Sutskever's "A Theory of Unsupervised Learning"
- LANGUAGE MODELING IS COMPRESSION
- The Theory of Knowledge: How Information & Knowledge are two sides of the same "bit"!
- Logic and Probability
- Understanding in Epistemology
后记
分享在看之前Ilya点赞的The Platonic Representation Hypothesis里面, 有一段很有意思的话.

神经网络必将走向智能.
附录
[1] 由于抽象能力很难定义, 所以这里简单把大语言模型的抽象能力定义为分词.
[2] 假如未来所有的对话(包括心理)都会以某种方式被AI伙伴记录, 并且AI伙伴百分之百是隐私安全.
[3] 在这个过程中我们不会用"学习". 理解是一种状态, 学习是导致理解的行为. 所以要达到理解, 不一定非得通过学习.
[5] 比较好的文章是这篇. 或者b站上的这个视频讲的很清楚.
[6] 在奇点降临(The Singularity Is Near)里面在2030年代意识上传将会出现.