记录一次对v4l2相机驱动的系统优化
背景
最近有个需求需要重新优化供应商提供的相机驱动的代码, 来实现更低的cpu占用率以及更好的实时性. 同时要发布的消息里的时间戳是相机曝光时间戳并且是以unix时间戳为基准. 平台为Jetson Orin. 需要做localhost ipc来让下游应用使用. 相机原始默认编码是yuyv, 需要转换成bgr发送.
之前从来没做过linux驱动之类的开发, 也没研究过图像转码, 有因为别的需求看过旧版相机代码. 整个任务自己从调研到实现大概花了两周时间, 其中一周卡在了视频编解码上面. 最后项目上面也没应用上. 因此开源了这个仓库, 算是给近期比较有意思需求的一个方案. 这篇文章将一步步的介绍并解决这个问题.
基于V4l2的相机驱动实现流程
首先, 旧版的相机驱动是基于v4l2的. v4l2就是linux提供的一系列api. 基于v4l2开发的驱动也是有一个比较固定的流程的. 大体如下:
1. 打开相机获得句柄
2. 准备好v4l2_buffer并且配置v4l2_buffer
3. 等待句柄事件触发
4. 事件触发后访问v4l2_buffer存的就是准备好的相机buffer(v4l2_struct)
此外相机是在硬件buffer里获取, 需要让用户态程序能够访问有三种方式dma, mmap和userptr. 我们希望尽可能低的cpu使用率因此选择dma. 因为其他两种方式相比, 从用户态程序操作buffer是直接对硬件buffer做操作 .而mmap和userptr都是对虚拟地址做操作的, 因此视频转码之后需要多一步I/O拷贝的硬件buffer.
了解了相机驱动大体流程之后, 首先先是尝试了v4l2_open()与open(), v4l2_ioctl()与ioctl()这些系统api的替换, 观察是否能有优化的效果. 经过一番尝试后发送如果换成v4l2_open()都无法打开用open()能打开的句柄.
图像转码
因为我们的平台是Jetson Orin. 自然会去想使用Nvidia提供的一些硬件视频编解码或者其他工具链路来完成, 比较直观的想法是在gpu上做yuyv到bgr的转换, 或者能直接在硬件buffer里面完成转码肯定是最好的. 所以先尝试了能否在硬件上直接做转码. 就开始了解Nv的工具链, Jetson Pack等等. 当然也会在Nv的论坛上看别人的post, 最开始看回答的时候也有些云里雾里的. 还有很多时候明明也没有解决方案,Nv也会把帖子标为solved. 当然这里不会过多论述踩坑的过程, 比较有帮助是下面这张图, 这张图展示了Nv的生态工具链:
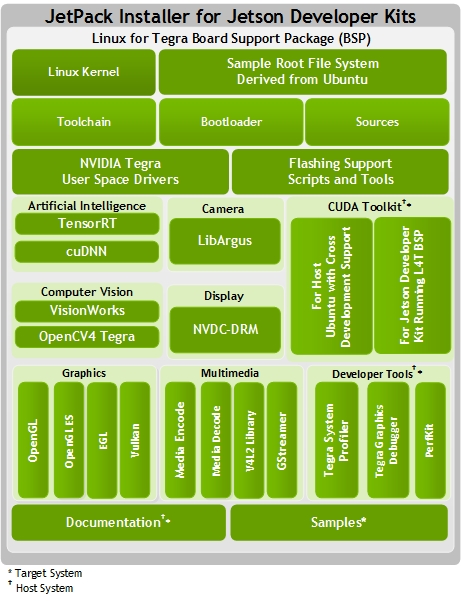
ok, 明确了大体上Nv所提供的工具链之后, 接下来解决这一步的问题: 原始相机吐出来的格式是YUYV要转换成BGR24, 在这一过程要达到性能最优.
根据上面的需求尝试了以下几个方案:
- 基于硬件的编解码,基于JetPack 5使用nvbuf_utils的NvBufSurface来存储相机原始数据buffer, 再使用NvBufSurfaceTransform
- 基于cuda做手动的转码,手写kernel. 根据这个公式, 一组YUYV可以转成成2个BGR像素. 以及jetson_multimedia_api的samples里面的转rgb的例子.
- 使用cuda加速版的opencv的cvtColor
- 使用Npp来做处理
尝试之后发现: 方案1: 硬件只能转换成BGRA, 因此要从BGRA转换成BGR的话. 不可避免的就需要在用户态开辟buffer做转换. 过程比较繁琐. 方案3: 性能相比于方案2要差, 猜测原因是cuda opencv不能自定义threads和block的比例. 方案4: 有奇怪的bug. 转出来的图片不符合预期,也没有论坛post去讨论这个问题. 因时间原因, 解不了只好放弃.
这一步最终选择了方案二. 使用CUDA Zero Copy Mapped Memory(host mem与device mem映射), 然后使用核函数去做转换.
时间戳对齐
相机驱动输出的结构体是v4l2_struct. 而v4l2_struct带的timestamp是相对时间戳(从系统上电开始计时)并且是Start Of Frame(即buffer里面第一个字节有数据时的时间),而需要转换到unix时间戳。那如何做转换呢? 通过clock_gettime函数里面, 传入两个timespec.一个为realtime另一个为monotonic. 再做差值就是两个尺度原点的差值. 此外, 还需要加RTCPU与CPU时间戳的偏移量(见链接):
t0 = adjusted_sof = TSC - offset_ns
TSC即下图的t1, 其中offset_ns代表latency.
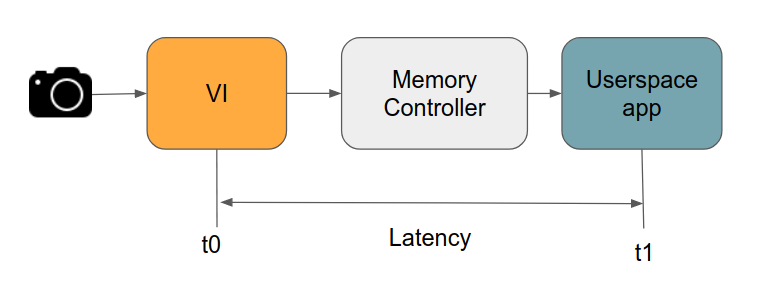
再补偿回这个偏移量就可以得到尺度一样的时间戳. 如果是在Nv的板上的话,偏移量会存放在/sys/devices/system/clocksource/clocksource0/offset_ns这个路径下. 加上了这个偏移量那输出的就是monotonic_time.
本机IPC(Inter Process Communication)
在编解码这一步我们使用了cuda开辟了gpu内存, 所以如果能基于cuda_ipc的话应该是最优解(没有多余的拷贝,客户端应用程序可以直接指向gpu buffer). 但是使用cuda-ipc的话就不能使用device和host memory的映射, 必须要cudaMemcpy. 并且我们希望cpu应用端也能直接拿. 接下来就考虑使用shared memory或者传dma_fd. 理论上传dma_fd的性能更高, 但是也依赖Nv的JetPack, 而刚好我们的JetPack版本在2023年12月这个时间点还不支持共享NvBufSurface. 如果以后支持了, 使用NvBufferTransformEx()类似这样的api应该是最优的做法.
还有, 可以用eglstream去做IPC, 比较麻烦的是每多一个订阅者就要改一次代码(开通channel). 因此也排除了基于Nv的生态做IPC.
现在考虑使用shared memory去做这件事. 有一个问题就是在应用端(驱动)去往内存块里写图片的时候, 客户端需要用进程锁. 如果这时候同步机制做的不好的话, 就很容易出问题. 一开始尝试使用boost的interprocess读写锁, 但是这里还是有内核态到用户态之间的切换. 基于纯用户态的话, 使用信号量做触发机制. 这样做是可行的, 但是对客户端接受编写接受图像代码逻辑有要求. 但还是有个问题就是这套机制没办法自定义QOS, 并且只限定于这种场景.
于是最终转向了Iceoryx. 因为这也是现有的基于shared memory(c++)最成熟的中间件. 相比于手写shared memory, 基于Iceoryx的通用性和可复用程序更高, 更有利于后续其他模块满足迁移通信机制的需求.
结果
做完上述处理过后的驱动相比于供应商提供给我们的驱动在cpu使用率在JetSon Orin上降低了10%左右. 如果你也有类似的问题, 参考这个仓库或许对你有所帮助.
总结
整个过程有以下几点总结:
- Nv的很多资料散落在论坛里面,需要多个post才能拼成一个完整的信息源.
- 问题最快的解决方式是直接让供应商找人去改. 能有时间和精力去研究这些当然好, 写完这篇文章或许能证明自己的一些学习能力. 但是所有问题的最快解决方案始终是找到对应的人. 因为很多问题遇到一次基本上也不会遇到第二次了, 很难说能从获得系统性的思考能力.
- 如果在现有的Nv板上在官方文档找不到解决问题的资料, 不妨往以前版本的Nv板的官方资料上面找.
参考资料
以下是在这过程中比较有帮助的参考资料:
- https://developer.ridgerun.com/wiki/index.php/NVIDIA_Jetson_TX2_-_Video_Input_Timing_Concepts
- https://forums.developer.nvidia.com/t/interprocess-zero-copy-image-transfer/231623
- https://on-demand.gputechconf.com/gtc/2016/webinar/getting-started-jetpack-camera-api.pdf