Nvidia CUDA的前世今生
Any sufficiently advanced technology is indistinguishable from magic. - Arthur C. Clarke
CUDA(Compute Unified Device Architecture)是Nvidia强大的护城河之一, 也绝对算是科技黑魔法.
最近突然冒出了一个想法, 为什么CUDA要这样设计(kernel, warp, thread, block, grid...)? 带着这个疑问, 我花了一些时间 在调研CUDA背后的历史, 以下是对Nvidia重要护城河之一的CUDA为什么这样设计的介绍:
CUDA发展历史
要了解CUDA为什么这样设计就需要了解CUDA的发展时间线. 在维基百科上搜索CUDA, 里面有提到CUDA的发展历史, 以下为原文:
Ian Buck, while at Stanford in 2000, created an 8K gaming rig using 32 GeForce cards, then obtained a DARPA grant to perform general purpose parallel programming on GPUs. He then joined Nvidia, where since 2004 he has been overseeing CUDA development. In pushing for CUDA, Jensen Huang aimed for the Nvidia GPUs to become a general hardware for scientific computing. CUDA was released in 2006. Around 2015, the focus of CUDA changed to neural networks.
谁是Ian Buck? 继续搜索Ian Buck会发现他现在英伟达的副总裁, 以前是斯坦福的博士生, 点击Ian博士时期的主页. 可以看到他在博士期间做的项目BrookGPU, 里面有提到Brook是Ian提出的针对与GPU编程的流式编程语言. 此外在CUDA1.0时期的采访,Ian在视频里面明确提到将Brook的想法迁移到CUDA上, 因此可以认为Brook就是CUDA最早的雏形.
Ian Buck的Brook语言
让我们一起再来看看BrookGPU的项目介绍:

总结一下, Brook提出了stream programming model以及stream application并给出了对应的实现去解决通用计算的问题.
再结合BrookGPU当时的论文Brook for GPUs: Stream Computing on Graphics Hardware以及Ian Buck的博士论文STREAM COMPUTING ON GRAPHICS HARDWARE. 我们能够了解到以下几个点:
- 由于GPU与CPU所针对的场景不同,并且由于CPU的局限性: 有限的instruction level parallelism (ILP), 过度使用缓存去获取局部性. 因此GPU的编程语言形态会与CPU有所不同.
- 当时也有针对于GPU编程的语言, 但是这些语言的实现都是针对于图形学的shader所设计的, 而不是为了通用计算编程所设计
- 程序在GPU上执行时,其内存访问延迟主要受到两个关键因素的制约: 一是计算速率(compute rate), 二是内存带宽(memory bandwidth). 这意味着,GPU处理数据的速度和内存传输数据的能力共同决定了程序在内存操作中的延迟表现. BrookGPU的设计是为了让GPU计算充分发挥, 从而让内存时延主要部分为内存带宽.
- Brook不是第一个尝试去解决通用计算问题, 但是是第一个使用流式处理(stream processing)去解决通用计算.

在Ian提出Streaming Processing框架的这一节提到了很重要的一个观点. 内存的访问速度(memory access rate)即内存带宽(memory bandwidth)往往 是制约程序性能的瓶颈. 而软件层由于改变不了物理的内存带宽, 因而会采取其他技巧去隐藏内存延迟(memory latency). 这里Streaming Processing使用data parallelism与arithmetic Intensity去隐藏内存延迟(hide memory latency). Ian也提出了什么是arithmetic Intensity的概念:
In order to quantify this property, we introduce the concept of arithmetic inten- sity. Arithmetic intensity is the ratio of arithmetic operations performed per memory operation, in other words, flops per word transferred.
感觉这里解释的不是很清楚, 于是询问GPT4的回答, 讲的很清楚:
 Arithmetic intensity指的是运算指令(add, mul..)与内存操作(load, store..)的比例.
Arithmetic intensity指的是运算指令(add, mul..)与内存操作(load, store..)的比例.
这里小结一下Brook做了什么事:
Brook是一种编程语言, 通过软件层的抽象来让程序尽可能得调用GPU的运算单元,尽可能减少内存搬运操作. 从而隐藏内存延迟.
如果有兴趣详细了解的话, GTC2022上的这个talk会很有帮助. 在了解了这些之后, 我们再来一起看看BrookGPU与CUDA的对比.
Brook与CUDA的对比
接下来结合上面的信息以及CUDA1.0的参考手册, 我们来看看Brook与Cuda的一些概念的对比. 由于CUDA是在Brook之后诞生, 所以这里以Brook中的概念为准分各个小节. 为了尽可能得传递原始信息避免加工, 每个概念会附上原文.
Stream
A stream is a collection of data which can be operated on in parallel. - Ian Buck, BROOK STREAM LANGUAGE p24
由于CUDA1.0里面没有Stream的概念, 这里没有直接查到是CUDA的哪一个版本提出了Stream. 所以参考了Steve Rennich在GTC的ppt.
A sequence of operations that execute in issue-order on the GPU - Steve Rennich, CUDA C/C++ Streams and Concurrency
Stream在brook指带的是一系统的数据, 而在cuda里面是的一系列的指令.
Kernel
Brook kernels are special functions, specified by the kernel keyword, which operate on streams. - Ian Buck, BROOK STREAM LANGUAGE p26
在Brook里面kernel指的是处理stream的函数. 由于stream是的是一系列的数据, 因此kernel也就是处理data的函数.
More precisely, a portion of an application that is executed many times, but independently on different data, can be isolated into a function that is executed on the device as many different threads. To that effect, such a function is compiled to the instruction set of the device and the resulting program, called a kernel - Nvidia CUDA Compute Unified Device Architecture Programming Guide, version1.0, p7
可以看到kernel在Brook与CUDA里面的概念是一致的. 都表示为处理数据的函数.
Reductions
While kernels provide a mechanism for applying a function to a set of data, reductions provide a data-parallel method for calculating a single value from a set of records. - Ian Buck, BROOK STREAM LANGUAGE p30
这里需要附上原文的代码才能更详细的说明:
// Task: Compute the sum of all the elements of a sum (a, r);
// Brook
reduce sum (float a<>, reduce float r<>) {
r += c;
}
float r;
float a<100>;
// Equivalant C code:
r = a[0];
for (i=1; i<100; i++)
r += a[i];
Reduction指的是将从一组数据中计算单个值的任务抽离出来, 很奇怪的一点是明明这里的操作也可以归为kernel的范畴, 但是Ian却单独抽里开. 说明Brook对Reducitons的实现与kernel是不同的. 而从语法上来看, 这段代码与CUDA调用kernel function几乎是一致的. 在CUDA中没有单独的概念, 说明这一操作已经在CUDA统一了.
到此为止, 我们已经了解了Brook里面提出的主要概念并且与CUDA里面的概念做了对比. 了解了Brook与CUDA之间的关系. 尽管Ian在自己的博士论文里面论述了Streaming Processing相比于SIMD的优势. 但是CUDA1.0的编程设计仍然是针对于SIMD Processor而不是后来的Streaming Processor. 而从2006年Ian的博士毕业到2007年CUDA1.0的发布. 中间肯定有受限于当时硬件设计的妥协. 说明任何事物发展都有个规律, 从概念提出最后到完全时间的周期往往会比较长. SIMD到SIMT也不是一蹴而就.
为什么CUDA这样设计
回到开头所提出的问题, 为什么CUDA这样设计? 结合Steve Jone在GTC2021的"How Gpu Computing Works"以及GTC2022的"How CUDA Programming Works", 我尝试用尽可能精炼的语言描述下我的理解:
从CUDA的目标上来看, 制约现在程序性能往往不是由于通常概念上的运算性能, 而是由于内存延迟. CUDA的任务就是让程序尽可能的调动GPU的运算单元, 从而隐藏内存延迟.
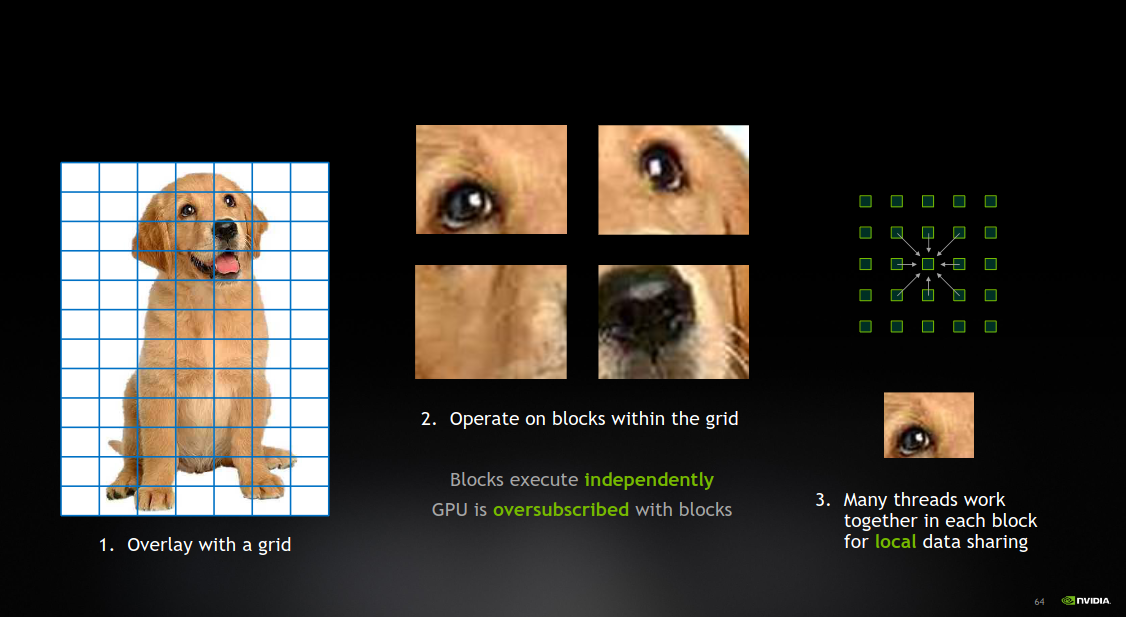
从CUDA的实现方式上来看, 因为GPU最开始是为加速渲染所设计并且适合执行大量重复的计算, 因此CUDA会有概念层的抽象. 通过将一张图片或者一次渲染做拆分成grid, 而每个grid会有多个blocks作为操作单元, 每个block的数据可以由多个thread来共享数据. 每个thread是最小操作单元. 通过这样划分, 实现了SIMT(Single Instruction Multiple Threads). 从而隐藏内存延迟.
下面这张图对于理解CUDA的概念非常有帮助:
总结
CUDA的发明者Ian Buck在读博士的时候(2006年左右), 当时已经有专门针对GPU的编程语言, 但是这些特点的语言的特定都是针对于图形学里的shader设计的, 因此不具有通用性. 因此CUDA的意义在于使用流式处理(stream processsing)去解决图形处理器通用计算(General-purpose computing on graphics processing units)软件层抽象的问题.
参考资料
- How Gpu Computing Works - Steve Jones
- How CUDA Programming Works - Steve Jones
- BROOK STREAM LANGUAGE - Ian Buck
- Brook for GPUs: Stream Computing on Graphics Hardware - Ian Buck
- Nvidia CUDA Compute Unified Device Architecture Programming Guide, version1.0
- Wikipedia